Abstract
校准(calibration),在机器学习公平性的背景下被重新重视
保证准确率的推荐,很容易导致:
1、用户的次要兴趣被主要兴趣挤出,使得推荐结果的领域逐渐趋向狭窄
2、当多个用户使用同一账号时,不活跃的用户的兴趣会被排挤
校准推荐(calibrated recommendations)可以避免这个问题
贡献:概述量化标准度的度量指标,后处理推荐系统输出的重新排序算法
INTRODUCTION
校准(calibrated):各个类别的预测比例与数据中的实际比例一致
校准推荐(calibrated recommendations):推荐列表能够反应用户的各种兴趣比例
校准的多样性:不同于项目之间最小相似性意义上的多样性,和推荐项的冗余
MOTIVATING EXAMPLE
离线数据集:由用户-项-交互历史数据组成,将其分为训练集和测试集
目的:保证最高准确度的情况下,在测试集中预测用户的交互项
假设:一个用户播放了70部“浪漫类”电影,和30部“动作类”电影
电影类别互斥
目的:生成一个包含10部电影的推荐列表
类别不均衡:
最极端情况:只知道用户对电影类别的喜好,没有任何其他电影的信息
为达到最高准确度,会100%为用户推荐“浪漫类”的电影,此时准确率为70%
如果随机为用户推荐电影,70%的概率推荐“浪漫类”,30%的概率推荐“动作类”,准确率只有
0.7 · 70% + 0.3 · 30% = 58%
因此,在保证准确性的前提下:
1. 在推荐结果中,用户的主要兴趣领域会被放大,而有轻微兴趣的领域会被排挤出去
2. 推荐结果是存在偏向的,偏向于用户的主要兴趣领域
反过来说,为提高平衡性,或者校准推荐,会降低推荐的准确性
考虑电影概率:

Latent Dirichlet Allocation(LDA):
受LDA的启发,用户选择电影的两步过程:选择类型,选择电影
提到LDA的原因:
1. 假设在现实世界中,用户确实按照以上两个步骤选择电影。LDA模型在训练时,能够以正确的比例捕获用户的兴趣平衡。推荐列表是迭代生成的,每次迭代增加一个推荐项,推荐项的得出遵循它的生成过程,即上述两个步骤:首先,类型g会根据p(g|u)被抽取出来;然后,电影i根据p(i|g)从类型g的所有电影中抽出。因此,即使电影i被选中的概率很小,也可以排进推荐列表的前方,但准确率比评分推荐低
2. 不平衡推荐的问题不仅限于显式类别,也适用于潜在主题或嵌入情况,LDA就是这样的模型
3. 不管电影是否属于一个类别,或属于几个类别,不平衡推荐的问题都会出现
CALIBRATION METRICS(校准度量)

CALIBRATION APPROACHES(校准方法)

RELATED CONCEPTS
多样性(Diversity):
多样性(Diversity)和校准(Calibration)的区别:
1. 多样性不能直接反应用户的兴趣比例:多样性即推荐项间的最小冗余或最小相似性,使推荐结果不是100%的“浪漫类”电影(在前面的例子中)。如果只有两种类型的电影,最多样性的推荐是50%“浪漫类”,50%“动作类”;如果还有其他类型的电影,多样性的推荐会把用户没有播放过的电影类型也推荐给用户,但如果把“动作类”电影在推荐中的比例由0%提升到30%以反映用户的兴趣比例,就不能保证多样性。只有把多样性和准确性平衡好,才能达到良好校准推荐。对于每个用户,这种折中的程度都是不同的。
2. 多样性可以推荐用户兴趣之外的电影,避免了推荐范围的减小(马太效应),而校准推荐没有这样的特性。这激发了对校准推荐的简单扩展,即用户兴趣之外的类别也会加入到推荐列表中:p_0 (g)表示每种类型的先验分布,取正数,为促进多样性
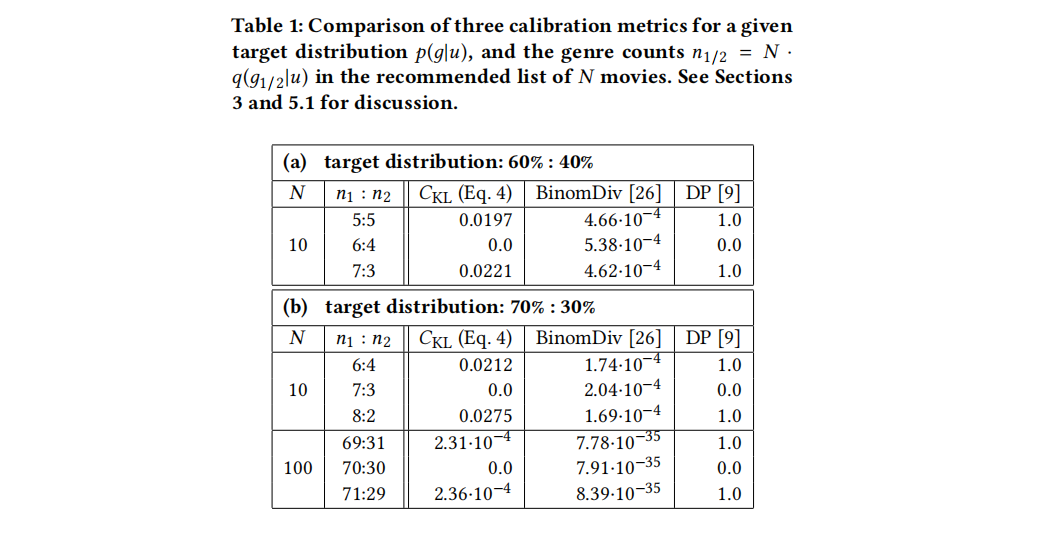
DP:本质上是p(g│u)和q(g│u)之间的修正平方差,符合仅我们提到的特性1
BinomDiv:符合特性2,3,劣势:无法给出推荐列表的校验程度(与目标比例的偏差),只能对不同推荐列表做相对比较;由于每个用户的兴趣比例不同,该方法不能简单的在用户之间进行平均,获得聚合度量
公平性(Fairness):
本篇文章中不考虑人之间的公平性,而是用户兴趣之间的公平性,也就是用正确的比例关系反应出来
为什么本篇文章认为校准标准(calibration criteria)在公平性中尤其重要:
校准、等可能性、等机会不能同时满足,除非两种情况:机器学习做出完美预测(在现实世界中不可能);不同组有相同的基本比率,即分类标签比例相同,通常在真实世界中也不可能出现。假设用户播放电影中70%是“浪漫类”,30%是“动作类”,那么这两种类型的基础比率很明显不同,两种类型电影的预测分数也会不同,因此,等可能性、等机会这样的公平性标准不能立即起适用
EXPERIMENTS





上述图标也反映了,经过校准后的推荐列表中的推荐项仍然是用户感兴趣领域的电影,因此有必要进行扩展校准(extended calibration probability),将用户兴趣之外的电影也加入推荐当中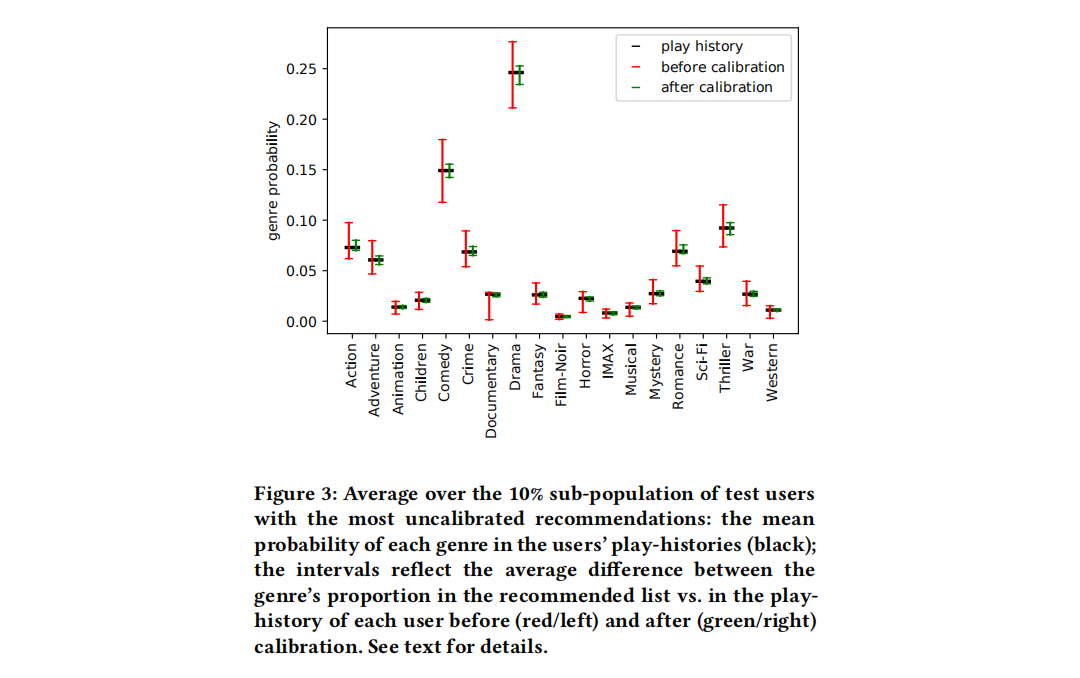
计算推荐列表中50部电影的类型概率和用户播放历史的类型概率之间的差异,然后对所有用户求平均值,区分差值的正负值
上图中,所有用户播放历史的类型概率的平均值是基准点,平均差值的正负决定了线段的长度,如果是完美推荐,那么线段长度应该为0。如果下面的线段比上方的线段长,那么这种类型电影的推荐与用户兴趣相比是过少的;如果上下一样长,那么这种类型电影的推荐在所有测试用户上的平均推荐比例是正确的(此外,上下方线段的长度还暗示了与每个用户兴趣比例的平均差距),要明确,推荐应该为每个用户都进行标准化,因此期望较小的线段长度
Documentary、IMAX、Musical、Western是under-represented(最下端接近0)
Action、Adventure、Crime、Mystery、Sci-Fi是over-represented(上端比下端长)
上图采用λ=0.99的校准度
CONCLUSION
本文是基于用户的角度,未来的研究工作将基于item的角度,比如一个item的推荐频率是否是另一个item的两倍,那这个 item很可能被选中(consume)的次数也是两倍的