本节课内容:
1、解决机器学习问题的大致步骤
2、使用误差分析来确定优化学习算法的方向
3、介绍查准率、召回率和F值的概念、定义及其意义
4、机器学习问题在什么情况下可以通过大量数据来提升算法性能
确定执行的优先级
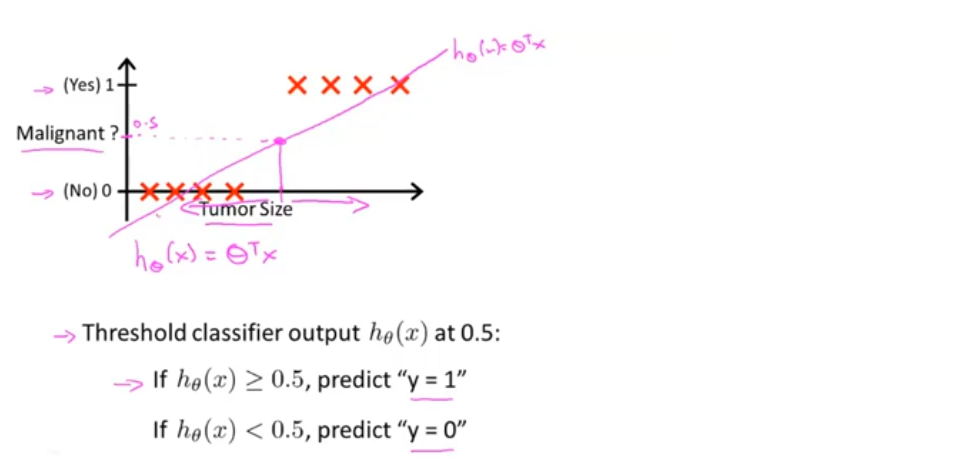
以垃圾邮件分类为例描述解决问题的过程
为了应用监督学习,首先想到的是如何来表示邮件的特征向量x,通过特征向量x和分类标签y,我们就可以训练一个分类器,比如使用逻辑回归的方法,这里有一种选择邮件特征向量的方法
我们提出一个可能含有100个单词的列表,通过这些单词来区分垃圾邮件或非垃圾邮件,假如有一封邮件,我们可以将这封邮件的各个片段编码成如下图的一个特征向量,先将找出的100个单词按照字典序排序(也可以不排序),当邮件中包含某个单词时,该单词出现在特征向量中的位置上置1,否则置0,最后我们可以得到100维的特征向量