第八章 对象的容纳
8.1 数组
- 对象数组容纳的是句柄,而基本类型的数组容纳的是具体的数值
- 对象数组创建之初会初始化为null,基本数据类型的数组会初始化为0(数值型)、null(字符型)或false(布尔型)
- 数组可以容纳基本数据类型和对象句柄,但集合只能容纳对象句柄,利用Integer、Double等“封装类”可以将基本数据类型的值置入集合中
8.2 集合
集合实际容纳的是类型为Object的一些对象句柄
(1)将一个对象句柄置入集合时,由于类型信息会被抛弃,所以任何类型的对象都可以进入集合中
(2)由于类型信息不复存在,所以集合能肯定的唯一事情就是自己容纳的是指向一个对象的句柄,正式使用集合中的对象前,必须对其进行造型,使其具有正确的类型
如果编译器期待的是一个String类型的对象,但实际没有给出String类型的对象,则会自动调用toString()方法,这个方法能生成满足要求的String对象
可以创建一个新类,只接受指定类型的对象
8.3 枚举器(Iterator)
作用:遍历一系列对象,并选择序列中的每个对象,同时不让用户程序员知道或关注那个序列的基础结构
“轻量级”对象,创建它只需要极小的代价
存在限制,如有些Iterator只能朝一个方向移动等:
例:Java的枚举类Enumeration,除下面这些外,不能再用它做其他任何事情:
(1)通过 elements()方法获取集合中的对象序列
(2)使用nextElement() 获得下一个对象,首次调用时会返回序列中的第一个对象
(3)用 hasMoreElements() 检查序列中是否还有更多的对象
若要保证枚举器枚举特定类型的集合,需对序列中的每个对象进行“下溯造型”
8.4 集合的类型
- Java标准集合里包含了toString()方法,它们能生成自己的String表达式,包括它们容纳的对象。例如在 Vector 中,toString()会在Vector 的各个元素中步进和遍历,并为每个元素调用 toString()。
- BitSet:由二进制位构成的Vector,最小长度是一个长整数(long)的长度64位
- Stack:后入先出集合,从Vector继承而来
- Hashtable:通过对象查找对象,从Dictionary 继承而来。Hashtable获取对象的HasCode(),然后用它快速查找键。Hashtable的toString()方法能遍历所有键-值对,并为每一对都调用toString()
- 当使用自定义类作为Hashtable的键-值时,需要覆盖hashCode()方法和equals()方法:默认的Object.equals()只是简单地比较对象地址(??:==比较对象地址,Object.equals()比较对象内容); Object 的hashCode()方法且默认情况下使用对象的地址来生成每个对象的散列码
8.5 排序
- 当创建一个排序Vector时,可以从Vector中继承,但由于一些方法有final属性导致不能覆盖,如要创建只接受String的排好序的Vector,需要覆盖addElement()方法和elementAt()方法,但他们都具有final属性,所以无法实现
- 考虑“合成”的方法:将对象置入新类的内部
- 除非绝对必要,否则就不采取行动的方法叫作“懒惰求值”(还有一种类似的技术叫作“懒惰初始化”——除非真的需要一个字段值,否则不进行初始化)
8.7 新集合
新集合考虑了“容纳自己对象”的问题,并将其分割为两个明确的概念:
(1)集合(Collection):一组单独的元素,通常应用了某种规则。一个List必须按特定顺序容纳元素,一个Set不可包含任何重复元素
(2)映射(Map):一系列“键-值”对。Map可以返回一个包含自己键的Set,一个包含自己值的List,或者一个包含自己“键-值”对的List
新集合之间的关系,其中虚线框代表接口,点线框代表抽象类,实线框代表普通类;点线白箭头表示接口的实现(抽象类则是部分实现),点线黑箭头表示一个类可生成箭头指向的类的对象:
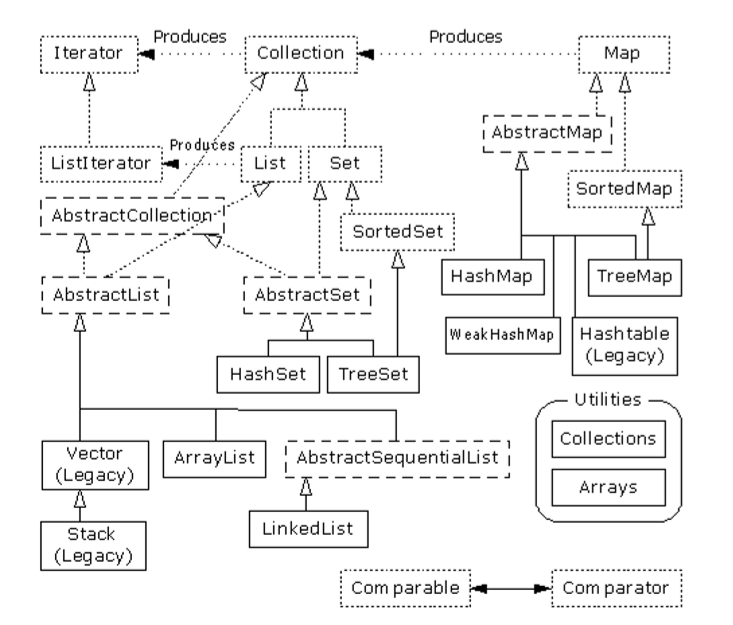
List:
- List接口:保证元素按照规定的顺序排序;可生成ListIterator,利用它在列表里朝两个方向遍历,同时插入和删除位于列表中部的元素(只建议对LinkedList这样做)
- ArrayList*:由一个数组后推得到的List;允许快速访问元素,但从列表中部插入和删除时稍慢,一般只用ListIterator对ArrayList进行遍历,不要用它进行删除和插入;与LinkedList相比,效率低
- LinkedList:根据常规的双重链接列表方式实现的;提供优化的顺序访问功能,同时高效地在列表中部进行插入和删除操作;但随即访问时,速度相当慢,此时应换用ArrayList
Sets:
- Set接口:不会添加重复元素;添加到Set中的对象必须定义equals()方法,从而建立对象的唯一性;不能保证顺序
- HashSet*:用于除非常小的以外的所有Set;对象必须定义hashCode()方法;使用散列函数
- ArraySet:由一个数组后推得到的Set;面向非常小的Set的设计,特别是需要频繁创建和删除的
- TreeSet:由一个“红黑树”后推得到的顺序Set,可以从Set中提取顺序集合
Maps:
- Map接口:维持“键 -值”对应关系,以便通过键查找相应的值
- HashMap*:基于一个散列表实现(代替Hashtable);针对“键-值”对的插入和检索,具有最稳定的性能;可通过构建器对这一性能进行调整,以便设置散列表的“能力”和“装载因子”
- ArrayMap:由一个ArrayList后推得到的Map;对反复的顺序提供精确控制;面向非常小的Map设计,特别是需要经常创建和删除的
- TreeMap:在一个“红黑树”的基础上实现;查看“键-值”对时会按固定顺序排列(取决于Comparable或Comparator);是含有subMap()方法的唯一一种Map,可以返回树的一部分
使用何种List:
- ArrayList(以及 Vector)是由一个数组后推得到的,而LinkedList 是根据常规的双重链接列表方式实现的
- 在ArrayList 中进行随机访问(即get())以及循环反复是最划得来的,但对于LinkedList 却是一个不小的开销;但另一方面,在列表中部进行插入和删除操作对于 LinkedList 来说却比ArrayList 划算得多
使用何种Set:
- 可在ArraySet 以及HashSet间作出选择,具体取决于 Set的大小
- 如果需要从一个 Set中获得一个顺序列表,请用TreeSet
- 进行add()以及contains()操作时,HashSet要比 ArraySet 出色得多,而且性能明显与元素的多寡关系
不大,一般编写程序的时候,几乎永远用不着使用 ArraySet
使用何种Map:
- 选择不同的 Map实施方案时,注意 Map的大小对于性能的影响是最大的,HashMap的性能优于ArrayMap(即使大小为10),所以当我们使用 Map时,首要的选择应该是HashMap,只有在极少数情况下才需要考虑其他方法
- TreeMap有出色的put()性能创建速度,且TreeMap是有固定顺序的
Arrays.toList()产生了一个List(列表),该列表是由一个固定长度的数组后推出来的,因此唯一能够支持的就是那些不改变数组长度的操作
排序与搜索 :
Arrays用于排序和搜索数组,Collections用于排序和搜索列表
Arrays类为所有基本数据类型的数组提供了一个重载的 sort()和 binarySearch(),可用于String和Object
若在执行一次binarySearch()之前不调用 sort(),便会发生不可预测的行为, 其中甚至包括无限循环
Comparator:针对Object数组(以及 String,它当然属于Object 的一种),可使用一个 sort(),并令其接纳另一个参数:实现了 Comparator接口(即“比较器”接口)的一个对象,并用它的单个 compare()方法进行比较;若用自己的 Comparator来进行一次 sort(),那么在使用binarySearch()时必须使用那个相同的 Comparator
原书示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//: AlphaComp.java
// Using Comparator to perform an alphabetic sort package c08.newcollections; import java.util.*;
public class AlphaComp implements Comparator {
public int compare(Object o1, Object o2) {
// Assume it's used only for Strings...
String s1 = ((String)o1).toLowerCase();
String s2 = ((String)o2).toLowerCase();
return s1.compareTo(s2);
}
public static void main(String[] args) {
String[] s = Array1.randStrings(4, 10);
Array1.print(s);
AlphaComp ac = new AlphaComp();
Arrays.sort(s, ac);
Array1.print(s);
// Must use the Comparator to search, also:
int loc = Arrays.binarySearch(s, s[3], ac);
System.out.println("Location of " + s[3] + " = " + loc);
}
} ///:~Comparable:Arrays类提供了另一个sort()方法,它会采用单个自变量:一个 Object 数组,这个 sort()方法也必须用同样的方式来比较两个 Object,通过实现 Comparable 接口,它采用了赋予一个类的 “自然比较方法”,这个接口含有单独一个方法——compareTo()
原书示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//: CompClass.java
// A class that implements Comparable package c08.newcollections; import java.util.*;
public class CompClass implements Comparable {
private int i;
public CompClass(int ii) { i = ii; }
public int compareTo(Object o) {
// Implicitly tests for correct type:
int argi = ((CompClass)o).i;
if(i == argi) return 0;
if(i < argi) return -1;
return 1;
}
public static void print(Object[] a) {
for(int i = 0; i < a.length; i++)
System.out.print(a[i] + " ");
System.out.println();
}
public String toString() { return i + ""; }
public static void main(String[] args) {
CompClass[] a = new CompClass[20];
for(int i = 0; i < a.length; i++)
a[i] = new CompClass((int)(Math.random() *100));
print(a);
Arrays.sort(a);
print(a);
int loc = Arrays.binarySearch(a, a[3]);
System.out.println("Location of " + a[3] + " = " + loc);
}
} ///:~列表:可用与数组相同的形式排序和搜索一个列表(List)。用于排序和搜索列表的静态方法包含在类 Collections中,但它们拥有与 Arrays中差不多的签名:sort(List)用于对一个实现了Comparable的对象列表进行排序;binarySearch(List,Object)用于查找列表中的某个对象;sort(List,Comparator)利用一个“比较器”对一个列表进行排序;而binarySearch(List,Object,Comparator)则用于查找那个列表中的一个对象;TreeMap也必须根据 Comparable 或者Comparator对自己的对象进行排序
Collections中的实用工具:
- 使 Collection或 Map不可修改:这个方法共有四种变化形式,分别用 于Collection(如果不想把集合当作一种更特殊的类型对待)、List、Set以及Map;对于每种情况,在将其正式变为只读以前,都必须用有有效的数据填充容器;为特定类型调用“不可修改”的方法不会造成编译期间的检查,但一旦发生任何变化,对修改特定容器方法的调用便会产生一个 UnsupportedOperationException违例
- Collection 或Map 的同步:新的集合库集能查出除我们的进程自己需要负责的之外的、对容器的其他任何修改。若探测到有其他方面也准备修改容器,便会立即产生一个ConcurrentModificationException(并发修改违例)。我们将这一机制称为“立即失败”——它并不用更复杂的算法在“以后”侦测问题,而是“立即”产生违例。