介绍
互惠环境(REs,Reciprocal Environments):在推荐时需要综合考虑推荐接收用户的偏好和被推荐用户的偏好,像求职类、约会类的应用,这类的平台或应用称为互惠环境
互惠推荐系统(RRSs,Reciprocal Recommender Systems):在互惠环境中为用户找到合适的匹配,称为互惠推荐系统
已经有研究工作证实,同时考虑双方的偏好的推荐方法,比只考虑推荐接收用户的偏好的推荐方法,更适合互惠环境
新的问题出现:RRS如何解释推荐原因
传统的解释方法(仅考虑推荐接收用户的偏好)已被证实,可以在非互惠环境中提升用户接受度(user’s acceptance rate)、用户主观满意度(user’s subjective satisfaction)、用户对系统的信任度(user’s trust),但是否适用于互惠环境尚不清楚
本文的主要工作
提出并评估了一种新的基于推荐双方偏好的解释方法,互惠解释(reciprocal explanations)
针对在线约会应用,分别在模拟数据和真实数据上进行实验,将互惠解释与传统解释方法进行对比,证明当推荐的是否接受被关联到某个权重时(发送私信花费的时间权重、担心被拒绝的感情权重等),互惠解释方法明显优于传统解释方法,因为此时提供互惠的解释,会提高用户对推荐的接受度和对系统的信任度;但如果这个权重可以忽略时,传统解释方法要优于互惠解释法
相关工作和背景
可解释人工智能(XAI,Explainable Artificial Intelligence)是一个新兴的领域,其目的是使自动化系统可理解。有大量的为推荐生成解释的方法已经被提出。
在推荐领域中常伴有以下两个习惯:
1)已有的解释方法仅关注了推荐接受者
2)已有的解释方法与特定的应用或特定的算法有很强的依赖,不能在不同的领域中很好的适用
许多研究也证实了为推荐提供解释是有好处的,结合许多研究工作,总结出两个在研究解释方法时被广泛认可的原则:
1)对被推荐用户/项目(item)具体特征的解释,会使推荐更高效,即使这些特征可能不是生成推荐的原因
2)限制解释的容量很重要,信息过载会适得其反
在线约会的推荐算法
本文的工作针对在线约会领域,主要研究解释的生成,使用在这个领域最先进的两个算法:RECON和双向协同过滤(Two-sided collaborative filtering)
RECON算法
用户x由两个成分定义:
1)A_x={v_a},用户x的个人属性值列表,v_a 是用户x对应a属性的属性值
2)p_(x,a)={(v_a, n)},用户x的偏好列表,n为用户x发送给a属性值为v_a 的用户的消息数量
e.g. Bob是一个男性用户,他给10个不同的女性发送过消息,假设用两个属性值描述一个用户:吸烟习惯(smoke habits)和身材(body type)。Bob发送信息的女性中,吸烟习惯的分布:1个经常吸烟(regularly),3个偶尔吸烟(occasionally),6个从不吸烟(never);身材的分布:4个苗条(slim),4个平均(average),2个强壮(athletic)。所以Bob的偏好如下:
p_(Bob,smoke)={(1,regular), (3,occasionally),(6,never)}
p_(Bob,body−type)={(4,slim), (4,average),(2,athletic)}
RECON算法通过启发函数预测每对用户x,y间的偏好,启发函数反应了两个用户间各自的偏好和对方的属性是如何校准的
双向协同过滤(Two-sided collaborative filtering)
双向协同过滤算法的性能优于RECON算法
相似度:根据历史消息计算用户间的相似度,如果两个用户都有大部分消息是发送给同一用户的,则认为两个用户是相似的
如果算法要向用户x推荐用户y:首先通过比较x与其他向y发送过消息的用户之间的相似度,得到x对y的感兴趣程度,然后再对称的计算y对x的感兴趣程度,最后将二者合并到一个单一度量中,表示x与y互相的感兴趣程度的匹配,最后再使用协同过滤进行推荐
生成互惠解释
假设根据上述算法为用户x推荐了用户y,将涵盖了用户x对y的兴趣的解释称为单向解释(one-sided explanation),记为e_(x,y)
将涵盖了用户x对y的兴趣,以及用户y对x的兴趣的解释称为互惠解释,互惠解释可以分解为一对单向解释,e_(x,y) 和e_(y,x)
实验研究
本文设计了3个实验,其中2个实验在模拟环境中进行,1个实验在真实环境中进行
MATCHMAKER模拟环境(简称MM)
在MM环境中,用户可以看到他人的基本信息,并与他人通过消息沟通
为了使MM中的用户基本信息尽可能真实,我们使用真实在线约会网站中的属性,但是这里的基本信息不包含用户的历史消息和偏好
信息收集:招募121位参与者,其中63名男性,58名女性,年龄在18到35岁之间(平均23.3岁),每个参与者都是单身的异性恋者。参与者首先进入MM系统,填写基本信息,然后看从真实网站中获取到的用户基本资料,并向他们 觉得合适的用户发送虚构的消息,在这个阶段,每个参与者都要至少看30分个人资料,并向至少10个人发送消息,目的是有充分的的数据来评估他们的偏好,最后平均每个参与者查看了50.72分个人资料(s.d.=30.99),向11.92个用户发送了消息(s.d.=3.96),由于没有遵从指示,有3名参与者的数据被删除
选择解释方法
我们返回最能解释为什么推荐的人是合适的k个属性来作为解释,为避免信息过载,限制k为3
实验两个解释方法:1)Transparent;2)Correlation-based
Transparent解释方法由RECON提供
为了向x解释推荐y的原因,该算法返回y的k个属性,在用户x所有发过消息的用户中,用户y的这k个属性表现得最突出
Transparent解释方法的算法如下图所示
correlation-based解释方法受机器学习中关联特征选择方法的启发产生
估计某用户的特征值v_a和用户x会向该用户发送消息的可能性之间的关联
对于用户x,定义I={i}为用户x查看过的用户集合,M_x(i)表示在用户集合I中x向哪些用户发送了消息,S_(x,v_a)(i)表示在用户集合I中哪些用户属性a的值为v_a
correlation-based解释方法的算法如下图所示
两个解释方法的区别
使用example2.1的例子:Bob查看过25个人的资料,其中“从不吸烟”的人有18个,“身材苗条”的人有4个,而Bob向6个从不吸烟的用户,以及4个身材苗条的用户发送了消息。假设k=1,Transparent算法会将“从不吸烟”作为解释而不是“身材苗条”,因为Bob向“从不吸烟”的用户发送的消息更多;Bob向1/3的“从未吸烟”的人发了消息,向全部“身材苗条”的人发了消息,correlation-based算法会将“身材苗条”作为解释
比较两种解释方法的性能
实验过程:
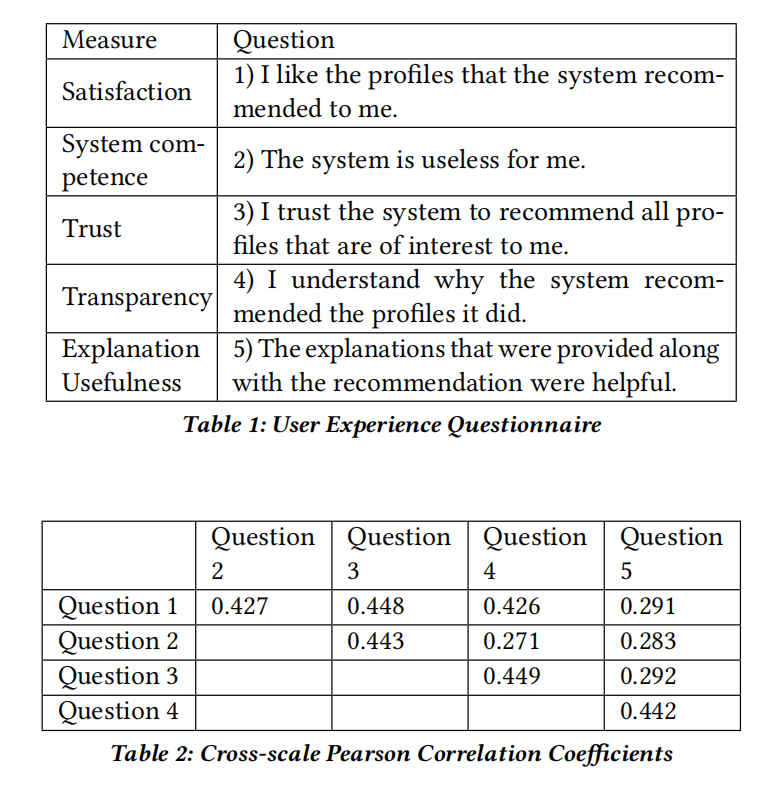
使用4.1中的MM系统,让118名参与者中的59名再次进入系统,他们每个人会接收到由RECON算法生成的推荐列表,其中包含5名推荐用户,在59个参与者中,30个人会收到transparent的解释,29个人会收到correlation-based的解释,我们要求参与者分别对5个推荐进行评估,满分为5分,此外参与者还要填写一份调查问卷(问卷内容在第7部分中),调查问卷主要包括:用户对推荐的满意度、系统的可用性、系统的可理解性、对系统的信任程度、对推荐的解释是否有用,所有的问题满分都是5分
实验中我们使用RECON推荐算法,因为双向协同过滤只能推荐发过消息的用户,本实验使用的系统不满足这个条件
实验结果:
使用correlation-based算法的解释比使用transparent算法的解释,在推荐满意度(mean= 3.58, s.d.= 0.82 vs. mean= 3.14, s.d.= 0.65,p ≤ 0.02)、系统可理解性(mean= 3.97,s.d.= 0.93 vs. mean= 3.41, s.d.= 0.65, p ≤ 0.04)、解释的有用程度(mean= 3.8, s.d.= 0.81 vs. mean=3.17, s.d.= 0.8, p ≤ 0.02)方面表现得更好,而在对推荐的评分、对系统的信任度、系统可用性方法没有明显区别
基于上述实验结果,我们采用correlation-based算法进行接下来的实验
在虚拟在线约会系统中的评估
已经有研究表明,不同的代价(cost),尤其是对被拒绝的担忧,对用户在系统中的行为有很大的影响,由于代价和潜在的利益在不同用户间是不同的,因此我们考虑两种模型:
1)考虑明确代价的模型:用户来评估推荐结果而不考虑任何明确的代价和利益,类似在4.2中的实验
2)考虑代价和利益
可忽略的代价
实验过程:
我们让剩余的59个参与者参与这个实验,每个参与者被随机分到如下两种情况的一种:1)使用one-sided解释(30人)2)使用互惠解释(29人)。每个用户再次进入系统中,接收到包含5个推荐用户的推荐列表,以及使用相应算法得到的解释,对推荐的衡量标准与4.2中类似
实验结果:
和期望的相反,几乎在所有的衡量标准上,ons-sided解释方法都优于互惠解释方法,如下图所示
由于样本大小相对较小,因此很难评估子群体之间和参与者之间的差异,例如女性群体,而在接下来的实验中我们有较大的样本数据集,我们可以对子群体进行统计分析
明确的代价
实验过程:
我们有招募了67名未参与过实验的志愿者,年龄在18到35岁(average= 24.8 s.d.=4.74),参与者会被随机分到one-sided解释或互惠解释,和之前的实验类似,参与者进入到系统中生成个人资料、浏览他人的资料 、向他们觉得匹配的用户发送消息,但在推荐阶段,我们人为的设置了代价和利益:当接收到推荐时,参与者可以选择是否向推荐用户发送消息。如果没有发送,参与者不会加分或者减分;如果发送了消息,假设对方给与了回复,参与者会得到和两人之间匹配度相同的分数(由RECON算法评估),假设对方未给与回复,参与者会丢掉3分。这么做的 目的是鼓励参与者向感兴趣的用户发送消息,同时考虑被拒绝的可能。每个参与者会接收到包含5个推荐用户的推荐列表,以及使用相应算法得到的解释。定义接受度(acceptance rate)为参与者选择发送消息的推荐用户数量,之后参与者同样要填写调查问卷。
实验结果:
和前一个实验结果不同,这次的实验结果显示,互惠解释方法要优于one-sided解释方法,如下图所示(这里的图可能有错误)
在真实在线约会应用中的评估
Doovdevan应用:为Android和IOS操作系统定制的web和移动应用程序,目前拥有大约32000名用户,并且正在迅速增长。我们选择他的原因是,在实验之前没有用户收到过推荐,这很重要,因为之前的推荐会影响用户对系统的信任度,以及用户对新的推荐的态度
这次我们使用双向协同过滤推荐算法
实验过程:
随机选取161个活跃用户(至少一周登陆一次),其中包括78个男性和83个女性,年龄在18岁到69岁之间(mean= 36.1, s.d.= 3.01),每个用户会被随机分到one-sided解释或互惠解释,出于对隐私的担忧,我们不允许向推荐接收者透露推荐用户的偏好,因此互惠解释包括两个方面内容:1)推荐接收用户对推荐用户的预期兴趣的解释,包括推荐用户的特定属性;2)系统认为推荐接收用户符合推荐用户的偏好,因此他/她可能会做出肯定的答复
每个用户同样接收到5个推荐用户,但不同的是用户每天会接到一个推荐,在这里,我们将接受度(acceptance rate)定义为用户发送了消息的推荐用户数除以用户点击了的推荐用户
实验结果:
实验结果显示接收到互惠解释的用户比接收到one-sided解释的用户的接受度更高(p<0.05),接收到互惠解释的用户接受度为53%,而接收到one-sided解释的用户接受度为36%。此外,我们发现相比男性群体,互惠解释在女性群体中表现的更突出;相比于经常发送消息的用户,互惠解释在常发消息的用户中表现的更突出,如下图所示
我们还统计了在推荐之后的一周内用户的登录次数,作为解释方法的另一个潜在影响,我们发现接收到互惠解释的用户明显登录得更频繁(56 log-ins compared to 23 log-ins,p<=0.05),这样的结果可能表明,收到互惠解释的用户对该系统更满意
讨论
上述的实验结果表明,解释方法的选择取决于用户遵循建议的代价(cost),在高代价的环境中,选择互惠解释方法更好,我们推测这是因为在互惠解释中,附加信息使得用户对接受推荐的结果感到更有信心;而在代价可忽略的环境中,one-sided解释则优于互惠解释,我们推测有两个原因:
1)信息过载:互惠解释包含更多的信息,如果推荐接收方认为这些信息不相关,则可能导致整个建议的有效性降低
2)用户通常以与其他人不同的方式来评判自己的喜好,用户对吸引自己的原因可能与生成的解释不同
我们进一步发现,并不是所有的用户都以同样的方式对解释作出反应,这可能意味着不太可能找到适用于所有人的解释方法,像遵循建议的代价就可能因人而异,比如男性更关注自己的喜好,而女性更关注自己对对方的吸引力
我们的主要贡献是引入了互惠解释并评估了它的有效性
需要注意的是,由于我们关注的是在线约会,上述结果并不能立即推广到其他互惠环境,例如招聘工作或室友匹配,互惠环境可能在其固有的担心被拒绝的情感成本上有很大的差异,这可能会影响互惠解释的有效性
总结
我们介绍了相互解释的用法,其中包括对建议双方在匹配中的假定利益的推理
我们对所提出的方法进行了评价,并将其与传统的片面解释方法进行了比较,并发现解释方法的选择应取决于用户接受建议的代价(例如情感代价),在高代价的环境中,选择互惠解释,而在代价可忽略的环境中,使用one-sided解释
附录