ABSTRACT
问题:传统的基于偏好的推荐没有考虑到用户的社交方面,一个值得信赖的朋友可能会指出我们一个与我们的典型偏好不符的有趣项目
目的:缩小基于偏好的推荐和基于社会关系的推荐之间的差异
方法:SPF(social Poisson factorization,社会关系矩阵泊松分解),一种将社交网络信息纳入传统分解方法的概率模型
效果:在6个真实数据集上的性能优于其他推荐方法
INTRODUCTION
研究表明,用户看中朋友对内容的发现和讨论意见,在线访问社交网络可以强化这种现象
矩阵分解方法不能利用这些信息,他能推断出你可能喜欢的物品是因为这个物品符合你的偏好,但是不能推断出你朋友喜欢且你也可能感兴趣的物品
本文提出基于贝叶斯矩阵分解的SPF(social Poisson factorization)方法,可以在社交层面反映用户消费的商品
SPF假设有两个信号驱动用户点击:对项目的潜在偏好和朋友的潜在影响
SPF推测每个用户的偏好和影响,向用户推荐即符合用户偏好又被其朋友点击过的项目
Related Work:
过去研究的一些缺陷:
1、假设用户影响(也称信任)是可以直接获取的,但除了是/否这样的二进制信任信息之外,其他的信任信息用户是很难输入的
2、假设信任是从网络结构中传播或计算得到的,忽略了用户活动,这可以反应用户对网络某些部分的信任
3、通过计算用户之间的相似程度来计算信任,会使一般意义上的偏好相似度和用户影响的概念混淆,比如:两个拥有相同兴趣偏好的用户可能各自阅读同一本书,但彼此之间没有交集
4、将社交信息纳入协同过滤方法中,与矩阵分解方法相比,缺乏可解释性
5、探索了传统的矩阵分解方法如何利用社交关系,例如许多模型分解了user-item数据和user-user网络,使相连用户的潜在偏好更接近彼此,反映出朋友有着相似的喜好
e.g. 如果用户喜欢某个项目只是因为他许多朋友也喜欢,这完全超出了他通常的喜好
本文思路:
寻找不同偏好的朋友(均衡朋友的影响),辅助向用户推荐不符合他通常喜好的物品。根据社交网络调整朋友的总体喜好,不允许用户仍然享受这种异常项目(朋友喜欢导致超出用户的通常喜好)的可能性
*注1:用户影响,即信任,是当两个用户是朋友有互动的前提下的,而通过偏好相似度计算得出的信任,很可能使非朋友的两个用户之间存在信任关系
*注2:假设用户可能喜欢某个项目,喜欢的程度是A;该用户的朋友也喜欢该项目,考虑到朋友的影响,再结合本身的喜好,导致得出该用户对该项目的喜欢程度是B;结果其实B是高于A的
SOCIAL POISSON FACTORIZATION
1、利用潜在用户偏好和潜在项目属性,捕捉用户的活动模式
2、估计用户受到朋友可见点击(朋友喜好)的影响有多大
3、推荐有影响力的朋友点击的项目,即使他们不符合矩阵分解得出的用户偏好
Background: Poisson factorization
泊松矩阵分解,即将通常的矩阵分解方法中的高斯分布换成泊松分布
Social Poisson factorization
SPF的思想:用户喜欢一个item有两个原因:用户的喜好和item的属性相符合(泊松矩阵分解/其他矩阵分解的思想);用户有喜欢这个item的朋友,或者他的许多朋友都喜欢这个item
在PF(泊松矩阵分解)中,每个用户有一个潜在喜好的向量。但每个用户又有一个对每个朋友影响力的向量。一个用户是否喜欢某个item取决于她潜在的喜好和item潜在的属性,也取决于对她有影响的朋友是否点击了它
Model specification(模型设定)
- 可用数据是用户行为和社交网络
- 行为数据是系数矩阵R,其中r_ui 是用户u点击项目i的次数
- 社交网络通过邻居集合表示:N(u)是连接到用户u的其他用户的索引集合
- 隐藏变量是每个用户的非负偏好k维向量θ_u,每个item的非负属性k维向量β_i,每个邻居的非负影响τ_uv
- τ_uv 表示用户u多大程度上受到用户v点击的影响
给定矩阵R的联合分布:

Forming recommendations with SPF(通过SPF形成推荐)

Learning the hidden variables with variational methods(用变分方法学习隐变量)
在给定了点击数据和社交网络的条件下,我们的目的是计算用户偏好、项目属性和潜在影响的后验分布
对于许多贝叶斯模型,SPF的精确后验分布是很难计算的
变分方法被广泛用于统计机器学习来适应复杂的贝叶斯模型
本文提出了基于变分方法的近似推理算法,通过这个算法,可以在非常大的数据集上计算近似后验期望
变分推理通过解决最优化问题逼近后验
1、在隐变量上定义自由参数化分布,将其参数拟合为近似后验分布
2、使用Kullback-Leibler散度来度量“近似度”,是一种对分部间距离的不对称度量
3、用拟合的变分布替代后验分布
EMPIRICAL STUDY(实验研究)
- 将SPF与五种涉及推荐中的社交网络的方法,和两种传统的矩阵分解方法,进行了比较
- 在6个真实数据集上,我们的方法优于以上所有方法
- 展示了如何利用SPF对数据进行挖掘,并从潜在因素和社会影响两个方面对数据进行了表征
- 评估了对潜在因素数量的敏感性,并讨论了如何在先验分布上设置超参数
数据集、方法和度量
6个数据集:
1、Ciao (ciao.co.uk):具有潜在社交网络的消费者评论网站,7K用户和98K项目的DVD评分和信任值
2、Epinions (epinions.com) :消费者评论网站,用户在网站上对商品进行评分,并将用户标记为可信赖的,包含39K用户和131K项目
3、Flixster (flixster.com):社交电影评论网站,我们将评分二值化,阈值设置在3或以上,从而得到132 K用户和42K项目
4、Douban (douban.com):一家中国社交网站,记录音乐、电影和书籍的评分,包含129K用户和57K项目
5、Etsy (etsy.com):一个手工制品和古董以及艺术品和工艺品的市场,用户可以互相关注,并将项目标记为收藏,这些数据由Etsy直接提供,筛选出了那些至少收藏了10项,并且至少有25%的项目与他们的朋友有共同之处的用户,我们省略了少于5个收藏的项目,包含40K用户和5.2M项目
6、Social Reader:一家大型媒体公司的数据集,在流行的在线社交网络上部署了一个阅读应用,数据包含一个社交网络和一个文章点击表,我们分析了2012年4月2日-6日的数据,仅包括在此期间至少阅读了3篇文章的用户,包含122K用户和6K项目
下表概述了6个数据集的属性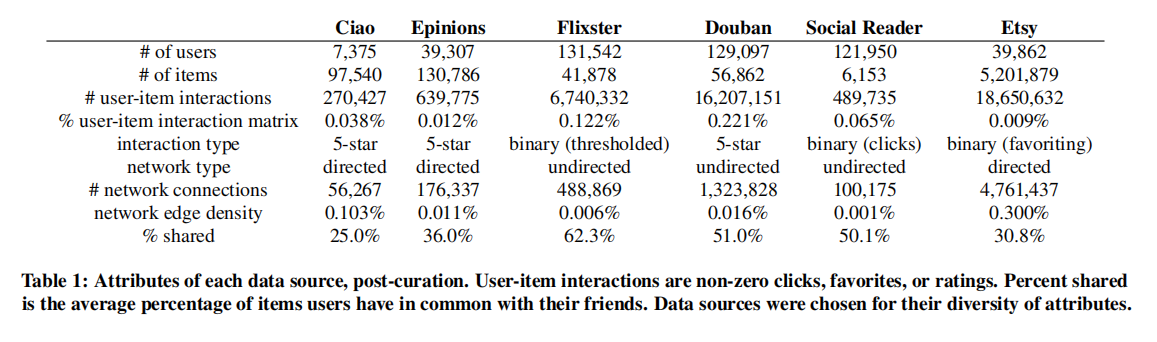
预处理:
对于隐式数据,非泊松模型要求我们对0进行子采样,以便区分项目;在这些情况下,我们随机抽样负示例,使每个用户都具有相同的正面和负面评分。请注意,基于泊松的模型隐式地分析了整个矩阵,而不需要支付分析零的计算成本
对于每个数据集,我们删除了用户没有共同项的网络连接。请注意,这对SPF和比较模型都有好处(虽然SPF可以了解邻居的相对影响)
将数据分为三组:约10%的用户数据用于推理后测试中(approximately 10% of 1000 users’ data),1%的用户数据用来评估推理的收敛性,其余的用于训练。一个例外是Ciao,我们使用了10%的用户数据进行测试(10% of all users’ data)
比较方法:
与以下几个模型进行比较:RSTE,TrustSVD,SocialMF,SoRec,TrustMF,以及概率高斯矩阵分解(PMF,广泛使用的推荐方法),对于每一个模型,采用最佳参数设置,与LibRec网站上发布的示例拟合
SPF有两个部分:泊松分解分量和社会分量,因此将这两部分单独比较:泊松分解(PF)和社会因素分解(SF)
比较两个标准,随机订购项目和根据普遍受欢迎程度订购项目
度量(NCRR):
对于每个用户,分别预测被搁置(held-out)项目的点击量,和真正未点击项目的点击量,并通过他们的期望值进行排名,好的模型应将搁置的项目排在前面
下图为实验结果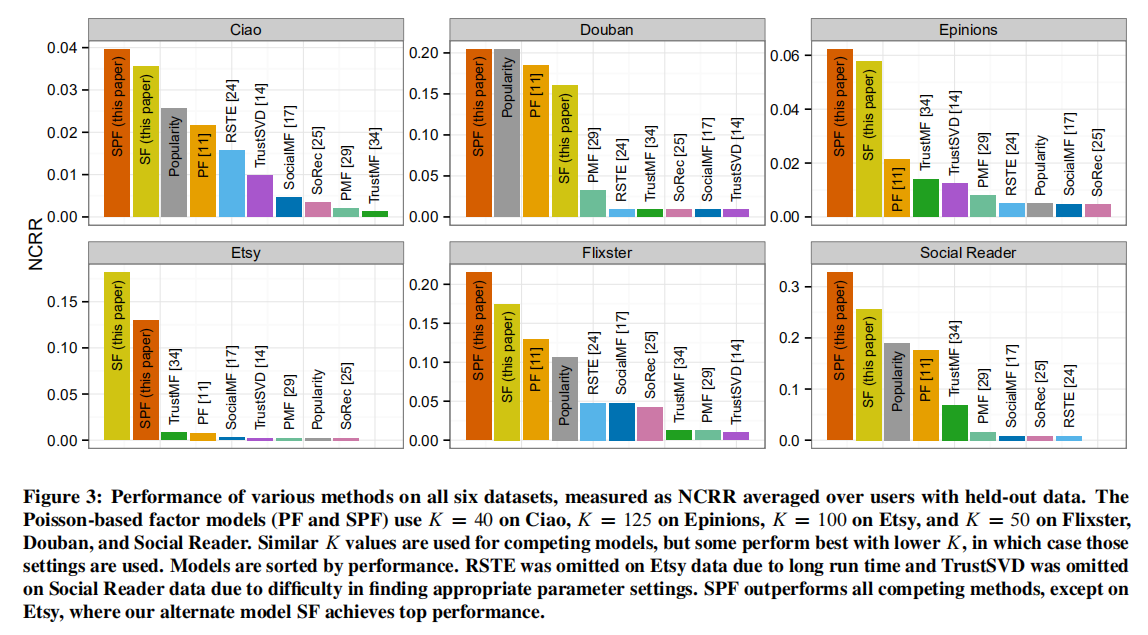
Performance and exploration(性能与探索)
性能:
各模型表现如图3所示,本文提出的SPF在所有6个数据集上的表现都优于其他模型,除了在Etsy上,纯社会因素分解(SF)表现最好。此外,基于流行度排序的表现良好,这突出了社会因素分解的重要性,只有SPF的表现一直优于它
在Ciao数据集上测量运行时,以了解相关的计算成本。下图显示了所有方法在K的不同值下的运行时,泊松模型在运行时方面是平均的
在Ciao和Epinionis数据集上,将SPF、SF和PF的性能看做每个用户的度的函数;结果如下图所示。所有的模型在高度的用户上都表现得更好,大概是因为他们的活动度更高。SPF的性能优于SF,因为它在大量的低度的用户上有优势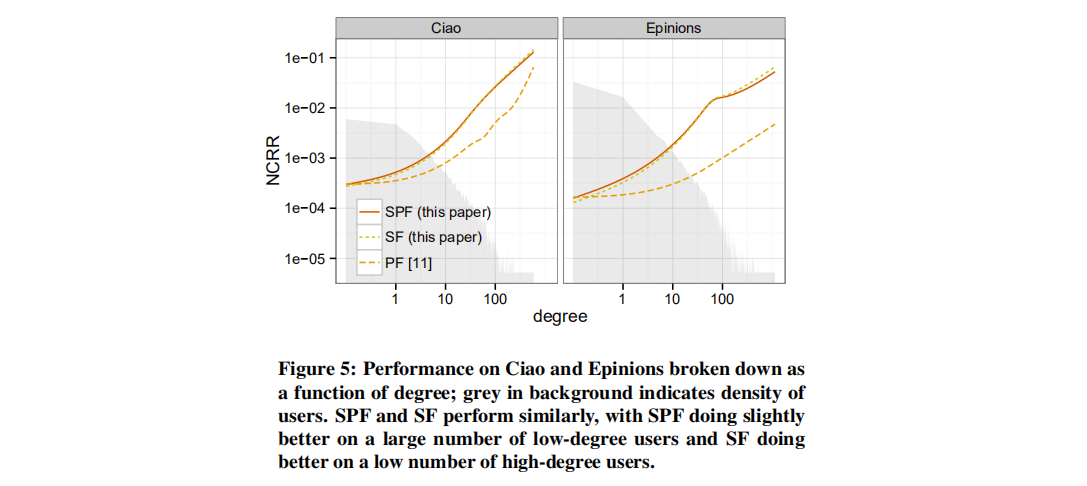
Interpretability(可解释性):
使用辅助变量将每个推荐归因于朋友或一般偏好,然后使用这些属性来探索数据
下图显示了在Ciao和Epinions数据集上,社会归因(与一般偏好归因相对)的比例如何随着用户度的变化而变化,观察到,Epinions将更大部分的行为归因于社会影响,并受用户度的控制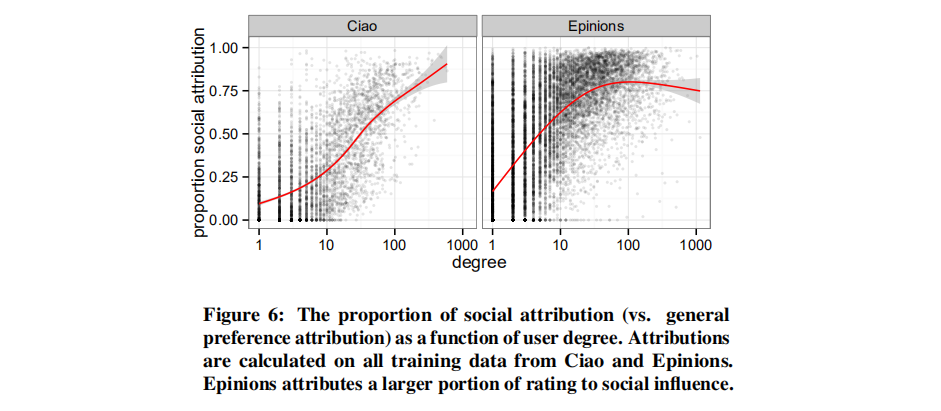
下图展示了社会影响与用户入度间的函数关系,在Epinions数据集上,高入度的用户比低入度的用户的社会影响更低
实验细节
潜在因子k值的选择:所有的矩阵分解模型,包括SPF,都要求选择用于表示用户和项目的潜在因子K的值,我们评估了Ciao数据集对K的敏感性,下图展示了K从1到500的平均NCRR,SPF在K=40时表现最佳,但对K敏感性低于其他一些方法(如PF)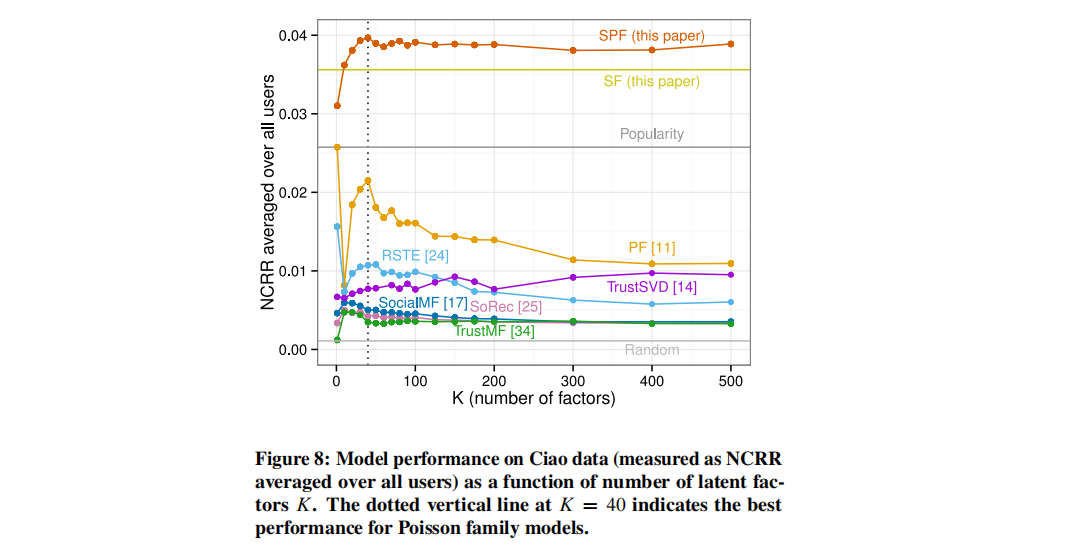
超参数:必须将超参数设置为潜在变量的γ先验, γ通过形状和速率参数化,将其设置为0.3,用于潜在偏好和属性的先验。 将先前用户影响的超参数设置为(2,5),为了鼓励模型通过社会影响来探索解释。 在一项试点研究中,我们发现该模型对这些设置不敏感。
在冷启动的情况下,我们知道用户的社交网络,但不知道他的点击项目,执行SPF相当于执行SF,SPF在这种冷启动的场景下比其他模型(本文提到的几个模型)表现都好
DISCUSSION
本文提出社会泊松分解(SPF),一种贝叶斯模型,结合了用户对其朋友潜在影响的项目的潜在偏好,我们证明,SPF即使在有噪声的社会网络上,也能改善推荐
SPF有以下特性:
1、它揭示了社交网络中用户之间存在的潜在影响,使我们能够分析社会动态。
2、它提供了可解释的意外发现的来源(???)
3、它具有可扩展的算法,适用于大数据集
我们的模型没有考虑到时间(当两个相连的用户都享受一个项目时,其中一个可能首先使用它)
论文原文
A Probabilistic Model for Using Social Networks in Personalized Item Recommendation